Yearly Archives: 2014
Dec 15, 2014 Jessica Silbey
In The Fight Over Digital Rights, Bill Herman, a professor in the Department of Film and Media Studies at Hunter College, explores the changing landscape of political debate over digital rights management between 1980 and 2012. This is a book about copyright, but it is also a book about political science and legislation.
You don’t need to know anything about copyright to read this book and learn new things about how the process by which legislation is formed and amended dramatically affects substantive and procedural rights. Herman’s book is about the rights and opportunities that copyright laws provide. And it traces the shape of those rights and opportunities as the legislative process has been affected by the rise of Internet activism since 1980.
One of the most refreshing aspects of Herman’s book is that despite its subject being copyright, its framework is not economic or social welfare theories that claim to unify or explain copyright protection. Herman’s book is about political history – the real nitty-gritty of coalitions, debates and compromises of copyright reform. Indeed, it is both a history and a road map of the copyright sausage factory. As such, it is a welcome departure from theories and reform proposals for what many consider to be a broken copyright system.
Herman gets real with this book. He demonstrates how a way forward to copyright reform that will enable creative practices of both users and authors (the dichotomy being a false one, in any case) requires both a comprehensive look at the path that produced the current Copyright Act and an understanding of how the digital tools the Copyright Act regulates are harnessed in a participatory democracy.
Herman begins with one of the first skirmishes between copyright and digital access that took place in the 1980s over the “digital audio tape” (or DAT) in the context of the passage of the Audio Home Recording Act (AHRA). He ends the book with a play-by-play analysis of the demise of SOPA (“Stop Online Piracy Act”) and PIPA (“Protect IP Act”) in early 2012. If the amount of acronyms in this paragraph isn’t already a clue, this book is candy for the gloriously geeky in the ways of technology and politics. It is also uplifting for those who worry that the legislative factory makes only one kind of sausage.
Herman employs both quantitative and qualitative analysis of political activity in the shape of media coverage, legislative filings and on-line communication to demonstrate the trend in copyright reform that reflects the growing influence of the Internet on advocacy and policy choices. Herman concludes that the demise of SOPA and PIPA is “the best possible evidence of the profound shift in the politics of copyright – an exclamation point on the internet-fueled [strong fair use] coalition” (203) brought about by “a potent group of political actors” and their “political messages communicated through new media.” (206)
Herman’s conclusion is that the “strong fair use” coalition (what he calls the SFU – as if we need more acronyms!) has become an effective political force in the copyright legislative reform. This is in large part because of the Internet (the largest and most accessible copy-machine in the world) that the Copyright Act tried, but has largely failed, to regulate.
In telling the story of the turning tides of legislative power over copyright law reform, Herman’s debt to Jessica Litman’s Digital Copyright is profound. ((Jessica Litman, Digital Copyright (2001).)) Litman was right in 2001 that copyright legislative reform has been the work of only the strong-copyright advocates (the big six movie studios (the “MPAA”), the music recording industry (the “RIAA”), and the text publishing industry (the Author’s Guild)). But Litman was writing only about the past – the 1978 Copyright Act and the 1998 Digital Millennium Copyright Act (“DMCA”). And her argument, although convincing and trustworthy, was also a battle cry for change.
Litman explained (and predicted) how captured legislative process concerning copyright results in benefits for an elite group of copyright holders and harms the everyday audience of copyright users and creators. (In today’s parlance, we might call the beneficiaries of these legislative reforms “the 1%”). Litman forewarned that if the past legislative process were predictive of the future, regulation of digital copyright (the dominant form of expression going forward) would suffocate the constitutional mandate for “progress” that requires distribution and access.
Herman’s book is less of a battle cry. Indeed, it is exhaustively descriptive of the legislative debates and media coverage of copyright reform over the past thirty years. Through the thicket of details about hearings, witnesses, publication venues, coalitions and media debates, Herman tells a normative story about the value of participatory democracy and his belief in its inevitability in the digital age. And that is because he believes the SFU coalition has begun to win some debates. (I question whether sinking SOPA and PIPA is a legislative “win” without the success of newly promulgated laws that instantiate the reasons those proposals were bad, but I will accept that their defeat is a step in the right direction for the SFU coalition).
Reading The Fight Over Digital Rights, I imagined Herman (metaphorically) taking Jessica Litman’s hand and following her back in time, retracing the legislative hearings of the AHRA in the late 1980s, the DMCA in the late 1990s, and then doing a deep dive into the media coverage surrounding both as well as substantial online communication concerning the latter. He does so not to make an argument about the normative benefits of strong-copyright or strong-fair-use (although as I said, it is hard not to read into his book a preference for the latter). His comprehensive discourse analysis, historical case studies, and quantitative measurements of media coverage are primarily about the value of evidence – evidence of the legislative capture Litman describes. And the value of his evidence reads like an antidote to Litman’s warning cry.
Herman shows how fights over copyright are between people, not only corporations, and this matters for how we mobilize on one side or the other and how successful our mobilization will be. And, because the Internet is the ultimate crowd-sourcing tool (in addition to a copy-and-distribution machine), the Internet has and will continue to affect politics and legislative change in the voice of the people using it.
Herman chronicles how the historic insularity of copyright reform has given way to public and political forums on the Internet. In the past, groups with greatest funding and political access have won policy outcomes of their choice by maintaining insularity and elite access; groups with less capital tend to take their case to the street, which lacked the continuity and strength of digital communication as it depended on everyday dedication of time and bodies. However, Herman says, the “internet reshapes policy advocacy … [and] mitigate[s] the problem of collective action.” (13) Because Internet communication is cheap, facilitates the aggregation and identification of communities of interest, and because it is durable and repetitious, it can even out the fight for access and rupture the insular spaces where legislative reform occurs. Herman shows how regarding the debate over SOPA and PIPA, by 2012 when the gears of the Internet were fully harnessed, “underfunded, diffuse group of citizens and nongovernmental organizations scored a victory against … concentrated well-funded industry group[s], highlighting the potential for online communication to shape policy outcomes.” (14)
Herman is not subtle about what he thinks the internet means for copyright reform and political processes generally. It is “nothing less than a fundamental reordering of the copyright policy subsystem.” (19)
As a dense political history, there is a lot that is new in this book, featuring industry leaders and legislators as battling protagonists. But there is also a lot that is left implicit which could be made clearer (with evidence and analysis) about the changing nature of the substance of the debate as the breath of its participants grow. As the medium in which the message circulates changes, how will the substance of the enacted policies also change? As the internet combines qualities of inestimable diffuseness with precision focus, Washington’s power-centers are destabilized and the influences legislators experience are more diverse. But the language of property entitlements and financial incentives is also still very present. These were the baselines of all past copyright reform. Will we hear something different this time around? Will the testimony on behalf of individual people or loosely-affiliated groups as opposed to well-established organizations and companies change what we understand copyright law to be for and how it works?
Certainly, the interests of the new and dominant technology companies that make devices that facilitate the making and dissemination of creativity are being heard (hello Google, Apple and Microsoft). But what about the creative people who are both hobbyists and professionals, who are artists, engineers, scientists, videographers, writers? Is Internet advocacy going to help them too? To answer this question, Herman’s book also traces the rise in public discussions of transparency in access to information, equality of opportunity to access intangible goods and the questionable benefits of exclusive entitlements. But his analysis on this score is thinner than on the expanding access to the legislative process more generally. Does his mention of these qualities mean that the individuals participating en masse through the Internet in debates over copyright care more about these issues than the other copyright interests (such as rights of excludability and maximalist revenue)? There is more research to be done on this score.
What do people who engage in creative practices and produce the work that companies sell need to continue their work? How do the existing laws (or hypothetical future laws) help or hurt their creative practices? Herman’s research leaves the reader with the impression – left to be proven in subsequent analyses and legal reform battles – that the change in access to law reform over copyright has changed the debate over the scope and nature of the rights copyright law should affect. If Herman is right, and the growing discussions about substantive equality and distributive justice will be durable features of IP policy going forward, we can say with some certainty that copyright law and policy is experiencing a transformation of both its substance and practice.
Nov 11, 2014 Kevin E. Collins
Tim Wu’s new essay, Properties of Information and the Legal Implications of Same, offers both a survey of recent legal and economic scholarship on information and a provocative reconceptualization of it. Wu posits that information is commonly described as an unusual resource because its very nature means that it possesses the twin properties of being non-excludable and non-rival. Taking these properties as givens, information can be readily pegged as a public good, and a strong case can be made out for government intervention to foster the production and/or dissemination of the information (whether in the form of IP rights, subsidies, or something else). However, Professor Wu’s reading of the literature, combined with his sprinkling of original comments on the intrinsic nature of information, suggests that the story is not quite this simple. (Although the review sweeps broadly, discussing securities regulation, contract theory, consumer protection, communications, and free speech, the bulk of it addresses intellectual property.) Professor Wu argues that information is not by its very nature non-excludable or non-rival. Rather, the subject matter of the information, the context in which the information exists, and the structure of the industry that employs the information all matter. They all affect the extent to which information is a public good. As a consequence, Professor Wu counsels against a single policy prescription for problems concerning the underproduction or under-dissemination of information and in favor of context-specific, dynamic laws governing information.
Professor Wu argues that non-excludability per se is not what makes information prone to free-riding problems (and thus the problem of underproduction without government intervention). Positing that information “consists of patterns, which must subsist in some form, whether ink on paper, stored magnetic charges, or whatever else” and that information is only valuable if a human mind perceives it, he takes it to be self-evident that people can in fact be readily excluded from information. “If you don’t have a ticket, you won’t see the movie, and we are all excluded from the text of a book locked in a vault for which the key is lost, or from the particular information contained in an engraving written in a lost language, like hieroglyphs before the discovery of the Rosetta stone.” Instead, Professor Wu suggests that information raises a free-riding concern because, among other things, it can often be copied at a relatively low cost. Presuming that copying costs vary, this shift in the conceptual framework for understanding what enables free-riding is significant because the argument in favor of government intervention shifts from being inherent in the essential nature of information to contingent on the particularities of the context in which information exists.
In a parallel argument, Professor Wu suggests that whether information is non-rival (and thus whether under-dissemination is a normative problem) may not be an intrinsic property of information, but may instead depend upon the type of information at issue or the structure of the industry in which the information is useful. Landes and Posner famously argued that characters like Mickey Mouse may be subject to “overgrazing” or congestion externalities; Kitch similarly argued that patents can be socially beneficial because they reduce the number of follow-on inventors who can use newly discovered technological information without the authorization of a coordinating entity. In sum, the fact that information is non-rival should not be taken as an intrinsic property of information as a resource. Rather, it is a variable with different values in different contexts.
In a short passage from his conclusion, Professor Wu nicely sums up the arguments discussed above and pivots to his take-home lesson:
It is … curious that, given the myriad properties of information, nonexcludability and non-rivalry have received so much attention. One may be suspicious that the attention may be prompted by its neatness of fit into the pre-existing concept of a public good more than the underlying realities of what information is. In any event, it is worth suggesting that lawyers’ or economists’ understanding of information’s properties might be broader, and begin to draw less on just anecdotal examples, but some study of the science of information. Indeed, it may turn out that information’s other properties, less studied, will be equally important for public policy.
In gross, Professor Wu taps into an important theme in the zeitgeist of contemporary intellectual property scholarship: information policy should not be constructed based on the presumption that there are universal truths about the intrinsic qualities of “information” (whatever it is), but rather on context-specific interventions to address particular problems.
I believe that legal scholarship would greatly benefit from greater precision when it discusses information. When we talk about information, we often talk in generalities that stand in the way of the more nuanced conversations that I think Professor Wu would like us to have. Does copyright prevent others from copying “information,” or is “information” what lies beyond the reach of copyright law because of the idea/expression and fact/expression dichotomies? Patent law is routinely described as an intellectual property regime that prevents others from copying “information” and “ideas,” yet “information” and “ideas” are also routinely described as the very resources that patent disclosures publicize and make freely available to all. Until we can pin down precisely what we mean when we say information we cannot begin to identify “information’s other properties” that are “less studied” yet that may well “be equally important for public policy” according to Professor Wu’s thesis. For example, Professor Wu himself distinguishes “knowledge” and “wisdom” from “information” at one point, without offering guidance as to how to draw the distinction.
I do have what I see as a friendly amendment to Professor Wu’s suggestion of a route forward. He suggests that we might draw on “some study of the science of information” to move beyond our myopic focus on non-excludability and non-rivalry. However, there is no single science of information. Scholars who study information are a diverse lot. Information theorists who follow Shannon, computer scientists, semanticists, semioticians, bioinformaticists, philosophers of technology, and cognitive scientists, among others, all point to different things when they pick out information in the world. Each discipline defines information in the manner that is useful to its own goals, and the disciplines rarely talk to one another. This balkanization complicates the mining of these disciplines for insights that are useful for economic and legal theorists: we will need to sort through the many taxonomies of information that have been proposed to find the ones which, given our goals, provide us with useful tools for identifying and understanding the information that concerns us.
In the English language, there is today no distinct word for the plural of “information.” Yet, I believe that “informations” would be a useful word to coin in order to highlight the true nature of the resource at issue and to facilitate the discussion that Prof. Wu would like to initiate. The point of the plural is not to make “information” operate like other count nouns; I’m perfectly happy with the notion that I buy information from you when I buy ten tips on ten distinct stocks. Rather, the model here is “fish.” The plural of “fish” is “fish” when all of the fish are the same species: “There are fish in the goldfish bowl.” However, the plural of “fish” is “fishes” when the speaker refers collectively to multiple species: “There are three fishes in that tank,” to the extent that the tank contains tuna, snapper, and flounder. To have intelligent discussions about information policy, we do more than realize that information exists in many different contexts; we must do more than seek context-sensitive policies to address the free flow of a unitary phenomenon called information. We must instead recognize that there are many different informations, each of which is studied by its own group of scholars and each of which may merit its own information policy, sometimes regardless of context.
Cite as: Kevin E. Collins,
Why FISH:FISHES :: INFORMATION:INFORMATIONS, JOTWELL
(November 11, 2014) (reviewing Tim Wu,
Properties of Information and the Legal Implications of Same (Columbia Law and Economics Working Paper No. 482, 2014), available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2446577),
https://ip.jotwell.com/why-fishfishes-informationinformations/.
Oct 10, 2014 David Fagundes
Mulligan, Christina,
The Cost of Personal Property Servitudes: Lessons for the Internet of Things (July 14, 2014). Available at
SSRN.
Property scholars have long noted a peculiar inconsistency between real and chattel property. While law increasingly tolerates different forms of ownership in and servitudes limiting the use of land, it has remained steadfastly resistant to such restrictions in the context of personal property. In her sharp new paper, “The Cost of Personal Property Servitudes: Lessons for the Internet of Things,” Christina Mulligan shows that this long-lamented inconsistency isn’t a problem at all, but rather a sensible distinction that flows naturally from the core differences between real and chattel property. This insight not only helps explain a longstanding puzzle in property law, but sheds new light on the increasing practice of content owners using license agreements to restrict the use of digital goods.
From a purely formal perspective, one might reasonably wonder why courts allow increasing complexity in real property ownership—from historical forms like contingent remainders and fees simple subject to executory limitation to modern innovations like condominiums and time-shares—while insisting that no such variation is permitted with respect to chattels. If I can have a defeasible fee interest or a time-share in a vacation home in Boca Raton, why not also in a Rolex or a refrigerator? This seeming has engaged scholars since Coke. Most recently, Molly Van Houweling investigated contract-based restrictions on personal property from the perspective of physical property, suggesting that the same concerns that warrant skepticism about servitudes on real property may be used to govern servitudes in the context of personal property as well.
Mulligan takes a different approach to this issue altogether. Instead of proposing a way to render uniform law’s treatment of real and personal property servitudes, she instead seeks a way to show that what other scholars have treated as a formal inconsistency actually rests on solid practical grounds. Mulligan deploys Merrill and Smith’s information costs defense of limited forms of property rights. Because chattels, unlike land, tend to be small, mobile and fungible, it will prove very difficult for a buyer to determine whether those chattels are heavily encumbered by restrictions or free for any sort of use. And since personalty tends to be worth less than land, these information costs will loom as an even greater burden to purchasers of chattel property than they would to real property. After all, it would be well worth the money to pay $1000 to clear title to a $200,000 vacant lot you’re thinking of purchasing, but you’d be a fool to shell out that amount to make sure there are no encumbrances on a $200 watch. And finally, Mulligan aptly observes that while one needs to investigate the state of title in real property relatively rarely, we purchase and interact with things all the time, so that in a world where we had to worry about use restrictions constantly, we would have to overcome information costs multiple times on a daily basis.
In answer to the longstanding question why law is conflicted in its treatment of servitudes on land and things, Christina Mulligan has shown us that the question itself is misconceived. There is not a conflict at all, but rather a perfectly plausible approach to managing the different information costs associated with real and personal property. Mulligan’s elegant information cost solution to this problem invites even more reasons that law may wisely choose to disfavor use restrictions on chattel property. Consider, for example, how information costs may play out in light of knowledge asymmetries between buyers and sellers of chattel property. Sellers’ greater knowledge and expertise would allow them to exploit information costs to systematically disadvantage end users. Imagine, for example, than an unscrupulous seller wants to sell books subject to a long, complex series of use restrictions, including the requirement that buyers will return the copy after six months of use. There’s a pretty good chance that many consumers will fail to smoke out this trap embedded in the Sargasso Sea of boilerplate—after all, it’s just a book, and hardly worth all the trouble of wading through a long agreement. But if law simply sidelines the whole idea of use restrictions on chattel property for a rule that says “when you buy it, it’s yours, no exceptions,” then we avoid this risk of consumer exploitation in addition to lowering information costs.
The nefarious bookseller in my example is hardly fictional. The Supreme Court’s 2013 decision in Kirtsaeng v. John Wiley Co. involved the legality of resale restrictions on textbooks sold in foreign markets, and most law professors have received at least a few desk copies plastered in big, ugly stickers reading “for professor use only.” The notion of imposing servitudes on chattel property may have been historically disfavored, but this apparently hasn’t prevented contemporary content owners from pushing the practice. In fact, as Mulligan correctly observes, use restrictions on personal property threaten to become ever more pervasive with the advent of the “internet of things”—the increasing enmeshment of everyday items with copyrighted software. Given courts’ peculiar toleration for use limits on software via licensing, and the ever-growing presence of computer programs embedded in cars, watches, and even refrigerators, long-rejected chattel servitudes may be approaching faster than we realize.
And here is where Mulligan’s focus on chattel property hits a normative wall. Information costs tell us a lot about why personal property servitudes are a bad idea, or at least a worse idea than they are in the context of real property. But the threat of pervasive, cost-prohibitive use restrictions on the countless things we own and use in our daily life isn’t merely, or even primarily, a property problem, but a contract problem. Software companies don’t regard themselves as selling copies of their programs that are subject to limited use rights. Rather, they portray these transfers as mere licenses, so that users are not owners of copies at all, but mere licensees, with the limits on their use—however draconian—flowing from the limited nature of licensure itself. So even if we agree—as Mulligan convincingly argues we should—that chattel property doctrine wisely disfavors use restrictions, this doesn’t answer the much harder question of what this means for owners’ ability to contract. And while there is no shortage of proposals for limiting how owners can license uses of their works of authorship, it bears remembering that owners are under no obligation to permit uses of their works at all, so a regime that excessively burdened their freedom of contract might lead owners to simply not contract—or engage in creative production—at all.
Scholarship should be measured by what it does, not by what it fails to do, and by that standard, Christina Mulligan’s “The Cost of Personal Property Servitudes” succeeds admirably. Her information-cost critique of chattel property servitudes not only helps to illuminate a longstanding puzzle in property law, but also moves the ball forward on the socially important and legally difficult issues raised by the increasing ubiquity of computer software in the objects that populate our daily lives. Mulligan’s insightful article also provides more evidence that there is more to be gained by investigating, rather than reflexively resisting, the essential commonalities between physical and intellectual property.
Sep 9, 2014 Rebecca Tushnet
There are many ways to use empirical research in intellectual property scholarship. Work can be qualitative or quantitative, interdisciplinary or highly focused on the law. One of the most intriguing questions I’ve seen investigated empirically of late is “what makes us think that one work is similar enough to a previous one to infringe?” Given the significant expansion in the scope of copyright from pure reproduction to derivative works and substantially similar works, this is an important issue.
The two articles I highlight here approach the question from very different, but complementary, perspectives. The authors of Judging Similarity start with legal scenarios adapted from real cases and ask survey respondents whether the works are similar enough to infringe. Kate Klonick, like David Morrison, examines similarity from a cognitive science perspective, starting with what researchers already know about human judgments of similarity and difference in nonlegal contexts. (Disclosure: I advised Klonick, now pursuing a Ph.D. at Yale, on this project.)
Judging Similarity begins by noting, as others have, that substantial similarity doctrine is a mess. They hypothesize that factfinders are more likely to find substantial similarity—and thus liability—in the context of “a narrative that not only describes the intentional act of making one thing look like another but also identifies a wrongdoer.”
In their control group, subjects had minimal information and were asked to judge the similarity of images; in the test group, subjects had additional information about “the act of copying, the creation of the work or the consequences of the copying.” Information about the fact of copying or that significant effort was required to create the first work increased similarity judgments, “despite the fact that the works themselves remained the same and even though the subjects were consistently told that they had to base their assessments entirely on the works themselves.” (Subjects weren’t making the on-off determination of substantial similarity that would be required in an actual copyright case; they were rating similarity on a scale; further work is needed to see how much this kind of information affects a threshold determination that could lead to liability.)
Morality, the authors suggest, affects factual judgments, fitting into a larger literature on motivated cognition. They argue that this isn’t just a question of framing—increased attention to similarity caused by the emphasis on the fact of copying—because information about the amount of labor involved in creating the original also increases similarity judgments. Given this effect, if we’re serious about keeping “labor = right” arguments like that rejected in Feist out of the copyright system, they suggest, the law might need to change further—or accept that labor-related considerations will come back in at the infringement stage, once certain works are deemed unprotectable. Copyright law’s claim to impose strict liability might be overstated, if we see respondents’ reactions as fault-based.
Intriguingly, however, information about market substitution, or the lack thereof, did not affect similarity judgments. The authors don’t have much to say about that result, but someone like me is inclined to read this as a moral intuition consistent with current fair use doctrine: if the copying is otherwise ok—if the work is transformative, and doesn’t displace a separate and robust derivative market like the market for film adaptations of novels—then the fact that it causes market harm is irrelevant. Reverse engineering cases and the idea/expression distinction that allows copying of ideas also follow this pattern. There’s nothing inherently wrong with giving people options to choose their favorite variations on a theme, even if one seller inspired others to enter the market.
Klonick’s article takes a different approach, focusing on other features of human thought, independent of moral principles. She notes that three significant areas of copyright law involve variations on judging similarity to and divergence from an existing work: (1) originality, where there is a public domain (or even copyrighted) referent and the question is whether enough has been added to create an original work; (2) infringement due to substantial similarity; and (3) transformativeness for fair use purposes.
She explains that cognitive scientists know some interesting things about similarity judgments. For one thing, there’s a difference between similarity judgments and difference judgments—depending on how a question is framed, respondents’ answers may diverge a lot. When asked to judge similarity, people give greater weight to common features; when asked to judge difference, they give greater weight to distinctive features of each item. For another, similarity judgments are not always transitive or symmetric. If you start with A and ask about its similarity to B, you can get different results than if you start with B and ask about its similarity to A. So, Americans asymmetrically found greater similarity in the phrase “Mexico is like the United States” than the phrase “the United States is like Mexico.” Consistent with this result, people are also more likely to find similarity when the more “prominent” idea or object is the referent—the B in “A is like B.” This phenomenon, she suggests, tilts the field in favor of owners of very successful works: in strike suits brought by owners of unsuccessful works, the accused work will be more prominent and will look less similar in comparison to the accusing work, while when the successful copyright owner sues, the accused work will look more similar.
In addition, depending on the situation, feature similarity may matter less than “relational” similarity—a bear isn’t a lot like a bird, but a mother bear with a cub is a lot like a bird with a chick. Consider the following images:
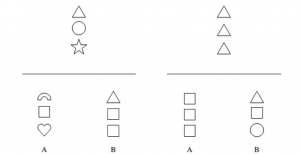
Most observers consider B (component or “primitive” feature match) more similar to the top stimulus in the panel on the left, but A (relational match) more similar to the top stimulus in the panel on the right. But this “relational weighting” also happens in difference judgments as well—so they are also likely to consider A more different from the stimulus than B is in the panel on the right.
Depending on how issues in copyright cases are presented, then, factfinders may be more inclined to find important differences or important similarities. She suggests that the Roth look and feel test might help moderate this effect, though I don’t really see how that would work. Klonick also suggests that transformativeness analysis’s shift to “purpose” can be explained in relational terms: when the question is how the new work fits into the universe of expression/what social role it plays, it may be easier to see relational differences, such as the difference between a single expressive work and a component of a large database (Perfect 10, etc.).
All of these features have implications for copyright cases, though they may be hard to tease out. At the very least, they offer guidance for savvy copyright lawyers trying to frame a case in a favorable way.
What these articles give us, especially taken together, are significant building blocks. They can be combined with other empirical work, such as Jamie Lund’s study showing that lay listeners simply can’t perform the task of judging infringment of musical works by listening to sound recordings, to suggest reforms to make practice fit theory. Jessica Litman’s recent article about the history of movie infringement cases also reminds us that we haven’t paid as much attention as we should to the fact that several foundational infringement cases involved moves from one medium to another—plays to silent movies, in her examples. What makes a dialogue-laden play seem similar or dissimilar to a mostly gestural movie is a question worth asking. As we gain a better idea of how people react to different comparisons, framing, and evidence, we can try to make both jury instructions and substantive law support the outcomes we believe to be the best for copyright policy overall.
Cite as: Rebecca Tushnet, Seeing Like a Copyright Lawyer: Judging Similarity in Copyright Cases, JOTWELL (September 9, 2014) (reviewing Shyamkrishna Balganesh, Irina D. Manta, & Tess Wilkinson‐Ryan, Judging Similarity, 100 Iowa L. Rev. (forthcoming 2014) and Kate Klonick, Comparing Apples to Applejacks: Cognitive Science Concepts of Similarity Judgment and Derivative Works, 64 J. Copyright Soc’y USA 365 (2013)), https://ip.jotwell.com/seeing-like-a-copyright-lawyer-judging-similarity-in-copyright-cases/.
Jul 28, 2014 Jason Schultz
Empirical studies of creative communities continue to provide scholars and policymakers with useful evidence for assessing intellectual property regimes. In Seven Commandments, we find yet another excellent example of the type of evidence we need to know and, perhaps even more importantly, robust methods for gathering it.
The article reports on a study of Threadless, an online community that crowd-sources t-shirt designs. As with many such communities, it uses a combination of collaborative and competitive elements, allowing users to work together on certain projects while also competing with each other for approval, funding, and ultimately production and distribution of the designed apparel. The authors of the paper seek to study the IP norms of the Threadless community in order to understand what makes it succeed in terms of incentives to create. In particular, they note that because formal enforcement of copyright law is generally difficult if not impossible on such sites, normative systems are presumed to play the major role in protecting the investment of creators.
In order to discover these norms, the authors gather data in three ways: netnography (observation on online communications and interactions), a survey, and a field experiment where the authors intentionally violated various designer’s IP by copying and posting some or all of their designs as new submissions on the Threadless site.
What they discover are seven “commandments” that appear to dominate the Threadless culture when it comes to IP norms. These include: (1) You must not make an unauthorized copy of a design; (2) If you copy, you have to ask the original designer for permission; (3) If you copy, you must provide attribution; (4) If you are suspicious of a design, you must investigate before accusing it of being a copy; (5) If you find that a design was copied, you have to make the copy case public; (6) the public trial must be fair; and (7) If someone is caught copying a design, you have to join in a collective sanctioning of the copier.
These results are somewhat surprising given the general skepticism that most researchers have had for crowdsourcing as a means of generating and enforcing norms, especially IP norms. Yet Seven Commandments shows that a large percentage of the active Threadless community has come to at least a rough consensus against unauthorized copying and for attribution. More interesting still, they have chosen to adopt some of the core elements of procedural due process from the court system as part of their approach to enforcement. For example, the notion that accusations of copying should be made public and that there should be some version of a public trial with evidence and the opportunity for the accused to contest and challenge the case against them goes back as far as the Magna Carta in Anglo-American law. Ironically, such elements are nearly absent from formal online IP enforcement/resolution regimes, such as the Digital Millennium Copyright Act’s “notice-and-takedown” scheme or the recent private agreement among United States Internet Service Providers to adopt a “six strikes” system of copyright complaints.
So what makes Threadless so special? How are they able to succeed in this regard? The authors are understandably cautious to pinpoint any one factor, but their findings suggest that there is a strong moral core to the approach of the community on these issues, and that the community’s commitment to this core allows them to have a more robust, participatory, and honest dialog about how IP should be handled. Moreover, there is a strong emphasis on the transparency of the community’s behavior. The accusations, evidence, trial, and sanctions are public and thus accountable themselves to any accusations of bias or abuse. This reinforces not only fairness but also rationality in outcomes.
Of course, Threadless is but one community, so one hopes that the authors of Seven Commandments expand their project to provide comparative results and analysis, especially across different modes and means of creativity, but by itself it serves as a beacon to help guide sites that want to avoid both unauthorized appropriation and excessive or draconian legal battles between community members




